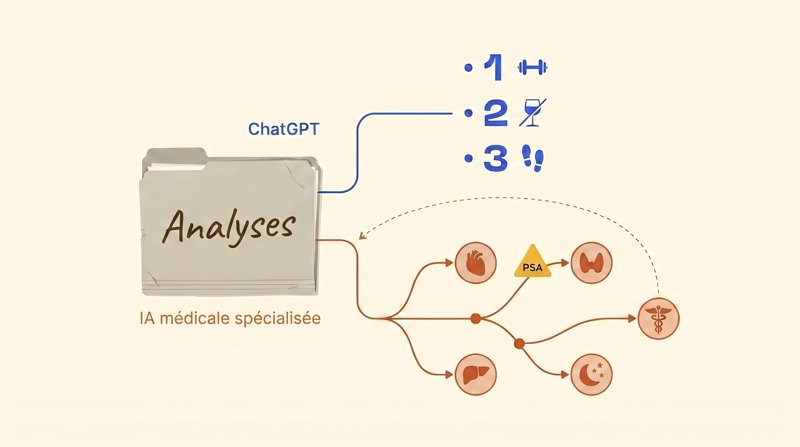
Nous avons chargé cinq cas cliniques dans ChatGPT et dans Wizey — les deux outils d’IA qu’un patient est aujourd’hui le plus susceptible d’ouvrir lorsqu’il essaie de comprendre un compte rendu de laboratoire — et nous avons demandé à chacun d’interpréter les mêmes analyses. Les deux IA sont parvenues au même diagnostic. Ce qui s’est passé ensuite fut inattendu, et cela change la question qu’il vaut la peine de poser à la technologie.
Deux réponses pour la même personne
Homme de quarante-cinq ans. Un jeu d’analyses. Une demande courte : « merci d’interpréter mes analyses ». Deux services. Voici ce qui est revenu — verbatim.
ChatGPT : Faites trois choses et la plupart des marqueurs se normaliseront. 1) Perdez 8-12 kg. 2) Alcool : presque tous les soirs en ce moment. Pour le foie et l’insuline, c’est critique. 3) Activité physique : un minimum de 8 000-10 000 pas par jour, plus de la musculation trois fois par semaine.
Wizey, l’IA médicale spécialisée : Endocrinologue — pour prendre en charge le prédiabète, l’insulinorésistance et discuter du traitement substitutif par testostérone. Cardiologue ou interniste — pour évaluer le risque cardiovasculaire. Gastro-entérologue ou hépatologue — pour confirmer la stéatose hépatique. Spécialiste du sommeil ou ORL — pour évaluer l’apnée du sommeil. Urologue-andrologue — pour un bilan approfondi de la dysfonction sexuelle. Dosage du PSA — obligatoire avant toute discussion d’un traitement par testostérone (dépistage standard chez l’homme de 45 ans et plus).
Une personne, un jeu d’analyses. Les deux IA ont correctement lu le tableau — syndrome métabolique, insulinorésistance, hypogonadisme fonctionnel, suspicion d’apnée du sommeil, carence en vitamine D et en zinc. Le diagnostic a concordé. Ce qui a divergé, c’est ce que cet homme devrait réellement faire au cours des deux prochaines semaines.
Nous sommes l’équipe derrière Wizey. En entamant cette expérience, notre pari de travail était que ChatGPT manquerait le diagnostic. Il ne l’a pas manqué une seule fois sur cinq cas. Le véritable constat a été tout autre : un diagnostic principal correct, ce n’est pas la même chose qu’aider le patient. À travers cinq cas, nous allons montrer où passe la véritable ligne de différence — et nous nommerons le seul cas où ChatGPT nous a battus sur la substance clinique.
Comment nous avons testé
- Nous avons assemblé cinq panels cliniques reconstitués à partir de cas réels publiés (PubMed, Blood, Annals of Family Medicine) — en préservant chaque anomalie et chaque symptôme cliniquement significatifs.
- Nous avons chargé le panel identique dans les deux services : ChatGPT (niveau Plus, GPT-5.4) et Wizey, une IA médicale spécialisée.
- Pour ChatGPT, nous avons saisi une demande courte : « merci d’interpréter mes analyses ». Pas de relance, pas d’ingénierie de prompt. L’objectif était de mimer ce que fait un patient ordinaire une impression à la main.
- Toutes les sorties ont été capturées verbatim. Les citations directes de cet article ne sont pas éditées ; les passages que nous avons raccourcis par souci de longueur sont signalés par des points de suspension.
- Quatre cas sont des scénarios ambulatoires de routine ; un cas bonus est urgent, inclus spécifiquement pour tester le comportement de triage.
Une note sur le périmètre
Cinq cas constituent une illustration d’un schéma, pas une statistique. Nous avons vu la même forme dans chacun des cinq, mais nous ne présentons pas cela comme une étude randomisée sur mille exécutions.
Nous sommes l’équipe de Wizey — le conflit d’intérêts est évident. Pour le compenser partiellement : la méthodologie a été figée avant les exécutions, toutes les sorties sont citées verbatim, et partout où ChatGPT nous a battus, nous le disons directement. Les publications sources à partir desquelles chaque panel a été reconstitué sont nommées dans le texte, de sorte que quiconque puisse reproduire l’expérience.
Tous les tests ont été exécutés sur une seule journée, le 17 avril 2026.
Ce que dit la littérature évaluée par les pairs
Pour les lectrices et lecteurs qui veulent les chiffres avant les études de cas, voici ce que la littérature évaluée par les pairs rapporte à propos de ChatGPT en interprétation de laboratoire :
- Cabral et al., PLOS ONE 2024 : sur des questions spécialisées de médecine de laboratoire, ChatGPT interprète correctement dans environ 51 % des cas, et 17 % des réponses sont purement et simplement fausses.
- Nature Communications Medicine, 2025 : lorsqu’une valeur médicale fausse est insérée discrètement dans le contexte du prompt, les LLM « doublent la mise » dans 83 % des cas — c’est-à-dire qu’ils acceptent la valeur erronée et construisent un raisonnement par-dessus, sans jamais signaler l’incohérence.
- Nature Scientific Reports, 2025 : sur les troubles mixtes de l’équilibre acido-basique, ChatGPT renvoie un verdict faussement rassurant de « normal » dans 16,7 % des cas ; les médecins de soins intensifs, sur les mêmes cas, affichent un taux de 0 % de fausses réassurances.
Les chiffres, pour le dire avec ménagement, sont alarmants. Mais il y a une nuance. Dans notre test sur cinq cas, ChatGPT a produit de façon fiable le diagnostic principal correct — y compris dans les cas où nous attendions qu’il trébuche : hypothyroïdie infraclinique, MGUS (gammapathie monoclonale de signification indéterminée), rhabdomyolyse induite par les statines, transition périménopausique, syndrome métabolique avec hypogonadisme fonctionnel. Cinq sur cinq.
C’est le véritable pivot de cette expérience. La différence n’est pas « bon ou faux », comme on a tendance à la formuler. La différence se trouve dans ce qui vient après le diagnostic correct. C’est la couche que nous allons décortiquer ensuite.

Cas 1 : quarante-cinq ans, fatigué d’être fatigué
Ingénieur de quarante-cinq ans. Travail sédentaire, un gros projet sous deadline, stress chronique. Plaintes : fatigue persistante qu’un week-end de repos ne répare pas, baisse de la libido, prise de poids, ronflements, céphalée matinale, reflux deux ou trois fois par semaine, douleur aux genoux. Alcool : un verre ou deux de vin presque tous les soirs, plus des spiritueux le week-end. Antécédents familiaux : père diabétique de type 2, mère hypertendue. Le classique homme d’âge moyen qui « a enfin pris le temps de faire des analyses ».
Anomalies clés du panel. HbA1c 5,9 %. HOMA-IR (indice d’insulinorésistance) 4,9, presque le double de la limite supérieure fixée à <2,5. Triglycérides 2,4 mmol/L, LDL 3,6, HDL 0,95, ApoB 1,35, indice athérogène 5,1. ALAT 58 U/L, GGT 78 — profil de stéatose hépatique non alcoolique (NAFLD). Testostérone libre 220 pmol/L, sous la plage. Vitamine D 18 ng/mL, zinc 9,4 μmol/L, B12 260 pmol/L, homocystéine 11,8. CRP-us 4,8 mg/L, acide urique 468 μmol/L, cortisol 580 nmol/L. Tour de taille 104 cm (normale <94).
Parité sur le diagnostic. Les deux IA ont produit la même liste : syndrome métabolique, insulinorésistance, prédiabète, dyslipidémie athérogène, NAFLD, hypogonadisme fonctionnel, carence en vitamine D et en zinc, inflammation chronique de bas grade, hyperuricémie, suspicion d’apnée obstructive du sommeil, cortisol dans la zone haute-normale. ChatGPT n’a manqué aucune pièce du tableau clinique. Il a assemblé chaque donnée honnêtement.
Maintenant — où les deux ont divergé.
Orientation des consultations. ChatGPT n’a nommé aucun spécialiste précis. Le bloc « où aller » consistait en « urgences » (réservées à la rhabdomyolyse, pas à ce cas-ci) et en formules du type « habituellement prescrit » ou « discutez-en avec votre médecin ». Wizey a déroulé cinq spécialistes avec leurs responsabilités spécifiques :
Endocrinologue — pour prendre en charge le prédiabète, l’insulinorésistance, évaluer la nécessité d’une correction pharmacologique des lipides et du glucose, et discuter du traitement substitutif par testostérone si les changements de mode de vie sont insuffisants. Cardiologue ou interniste — pour évaluer le risque cardiovasculaire. Gastro-entérologue ou hépatologue — pour confirmer la stéatose hépatique. Spécialiste du sommeil ou ORL — pour évaluer l’apnée du sommeil. Urologue-andrologue — pour un bilan approfondi de la dysfonction sexuelle.
— Wizey
Dans la plupart des systèmes de santé, voir cinq spécialistes en deux semaines est irréaliste — le parcours avec le médecin traitant comme filtre est plus réaliste, et même avec une assurance privée, aligner cinq consultations prend un mois. Mais au moins, le patient sait qui il va voir et pourquoi. « Discutez-en avec votre médecin » est une non-réponse quand les délais d’attente typiques en endocrinologie se comptent en semaines, voire en mois ; le patient ouvre simplement un autre chat d’IA. Ou pire — il commence à s’auto-traiter. Ou il perd simplement un temps qui compte.
La couche de sécurité — la plus grosse omission. ChatGPT a signalé la testostérone libre basse et expliqué les causes. Il s’est arrêté là. Wizey l’a intégrée comme un point à part entière :
Dosage du PSA (antigène prostatique spécifique) — obligatoire avant toute discussion d’un traitement par testostérone. Dépistage standard chez l’homme de 45 ans et plus.
— Wizey
Ce n’est pas une pinaillerie. Le traitement substitutif par testostérone (TRT) en présence d’un cancer de la prostate non diagnostiqué peut accélérer la progression tumorale — le dépistage du PSA avant l’initiation du TRT figure dans la plupart des recommandations pertinentes (Endocrine Society, AUA, entre autres). Un homme de 45 ans qui lit la sortie de ChatGPT et part chercher un TRT dans une clinique boutique sans PSA, c’est un échec clinique réel qui n’attend que de se produire. Le guide de traitement par testostérone de l’Endocrine Society est sans ambiguïté sur ce point.
Cibles quantitatives. ChatGPT : « Vitamine D3 4000-5000 UI, magnésium 300-400 mg, zinc 20-30 mg, oméga-3 2-3 g, complexe B. » Wizey sur la même question :
Vitamine D — avec un taux sérique de 18 ng/mL, la posologie typique est de 2000-5000 UI/jour pour atteindre une plage cible de 40-60 ng/mL. Recontrôle à 2-3 mois. Zinc — 15-30 mg sous forme de picolinate ou citrate. Magnésium 300-400 mg sous forme de citrate ou glycinate. Oméga-3 (EPA+DHA) 1000-2000 mg. Berbérine ou inositol — à discuter avec votre endocrinologue.
— Wizey
La différence, c’est « combien en prendre aujourd’hui » contre « quel taux atteindre, quelle forme choisir, quand recontrôler ». Avec la première indication, le patient prend de la vitamine D sans savoir si ça fonctionne. Avec la seconde, il y a un point de contrôle.
La cascade mécanistique. ChatGPT a fourni des tableaux et des listes à puces : voici la glycémie, voici l’insuline, voici le LDL. Wizey a déroulé huit maillons causaux numérotés :
1) La graisse viscérale n’est pas un simple stockage — c’est un tissu endocriniennement actif. Elle libère des signaux inflammatoires, abaisse la sensibilité à l’insuline et convertit la testostérone en estradiol. 2) Insulinorésistance → le pancréas produit davantage d’insuline → l’insuline stimule la synthèse hépatique des triglycérides et du LDL → dyslipidémie. 3) Cortisol élevé → aggrave l’insulinorésistance et supprime la testostérone. 4) Alcool quotidien → élève les triglycérides et la GGT, perturbe le sommeil. 5) Carence en vitamine D et en zinc → réduction de la synthèse de testostérone. 6) Testostérone libre basse → perte de masse musculaire → métabolisme ralenti. 7) Ronflements plus céphalées matinales → apnée → fragmentation du sommeil → cortisol + insulinorésistance. 8) Antécédents familiaux — charge génétique.
— Wizey

C’est la carte mentale qu’un bon clinicien tient en tête. Avec elle, le patient cesse d’être un passager dans sa propre physiologie : perdre du poids, arrêter le verre du soir et utiliser la PPC pour l’apnée ne sont plus trois actions sans rapport — ce sont les parties d’un même système.
Cadrage émotionnel et pronostic. ChatGPT s’en est tenu à un énoncé clinique neutre. Wizey a ajouté un cadrage court mais important :
Bonne nouvelle : la plupart de vos problèmes sont réversibles… Si vous agissez maintenant, le pronostic est excellent — tout peut être inversé. Votre situation est typique d’un homme moderne d’âge moyen. L’important, c’est que vous l’ayez détectée à temps. Beaucoup de gens ne consultent qu’une fois déjà diabétiques, ou après un infarctus.
— Wizey
Ce n’est pas de la thérapie. C’est de l’information pronostique — « agir maintenant compte, il n’est pas trop tard » — plus une orientation : « votre cas n’est pas inhabituel ». Pour un homme de 45 ans qui fixe un panel avec vingt marqueurs anormaux, la différence entre un diagnostic sans émotion et un diagnostic plus la reconnaissance qu’un rétablissement reste possible est psychologiquement significative.
Là où ChatGPT a gagné. Lp(a) — avec des antécédents familiaux de coronaropathie, c’est un marqueur cardiaque important que nous n’avons pas mentionné. La formule condensée des « trois choses à faire » (poids, alcool, activité) est mémorable et motivante. Échographie des carotides comme dépistage d’athérosclérose. Vraies victoires pour ChatGPT sur ce cas.
Conclusion du cas. Parité sur le diagnostic. Divergence sur « que fait réellement cet homme dans les 14 prochains jours ? ». ChatGPT a donné une formule motivante en trois actions. Wizey a donné cinq spécialistes avec des responsabilités spécifiques, le garde-fou PSA-avant-TRT, des cibles quantitatives avec des intervalles de recontrôle, une cascade mécanistique, un pronostic et la réassurance que le patient arrivait à temps.
Un diagnostic principal correct, c’est zéro minute d’aide réelle s’il n’y a pas de parcours de consultation, pas de contrôle de sécurité, pas de niveaux cibles et pas de cadrage « vous êtes à temps » derrière.
Sept différences entre les services
Pas une statistique sur cent cas — un schéma observable sur cinq, répété sur chacun. Nous avons comparé les sorties ligne par ligne sur sept paramètres.

Le tableau n’est pas une déclaration selon laquelle « ChatGPT perd ». C’est une carte des points où les deux services divergent. Sur la question rapide du « ça veut dire quoi, au juste ? », ChatGPT est rapide et bon. Sur le plan d’action avant la consultation médicale, il s’affaisse de façon systématique. Ce n’est pas un bug : GPT a été entraîné sur du texte hétérogène d’internet, pas sur des algorithmes cliniques de prise en charge du patient.
Là où ChatGPT nous a battus — en toute honnêteté
Nous avons fait passer le cas de MGUS (gammapathie monoclonale de signification indéterminée) dans les deux services — et ici ChatGPT a gagné sur la substance clinique. Nous avions promis dans notre méthodologie de nommer nos ratés directement. En voici un.
Homme de soixante-huit ans. Plaintes — faiblesse généralisée depuis six mois et lombalgies intermittentes. Sous périndopril et atorvastatine 10 mg. Panel presque normal à l’exception de trois résultats : protéines totales 92 g/L (élevées ; normales 64-83), albumine 38 (normale), VS 38 mm/h (plus du double de la limite supérieure). Âge 68 + six mois de faiblesse + lombalgie + protéines totales élevées + VS élevée = la classique « triade d’alerte » de gammapathie monoclonale ou de myélome multiple. Cela doit être repéré au dépistage.
Ce que ChatGPT a mieux fait. Il a explicitement calculé le rapport albumine/globulines : protéines totales 92, albumine 38 → globulines 54, rapport 0,70 (normal >1,0). Conclusion : globulines élevées. À partir de là, il a nommé un diagnostic différentiel spécifique :
Trois signaux d’alerte : VS 38, protéines totales 92 et le profil symptomatique (faiblesse plus lombalgie). Cette association justifie classiquement d’écarter un myélome multiple… Peut aussi évoquer : inflammation chronique, infection, maladie rhumatologique, MGUS.
— ChatGPT
Et il a donné un bilan spécifique : électrophorèse des protéines sériques + immunofixation + chaînes légères libres (FLC) + protéine de Bence-Jones dans les urines + radiographie/IRM du rachis + TDM osseuse. C’est une vraie liste clinique — exactement ce qu’un hématologue prescrirait. C’est la différence entre « bilan de MGUS » et « bilan d’une VS inexpliquée ». Selon la récente couverture de NEJM AI sur GPT-4 en cas cliniques, les listes de diagnostic différentiel spécifiques à l’hématologie font partie des domaines où les modèles de frontière se sont nettement améliorés.

Ce que Wizey a manqué. Nous n’avons pas explicitement calculé le rapport A/G. Nous avons mentionné les gammapathies monoclonales comme possibilité, mais nous n’avons pas nommé les examens confirmatoires spécifiques — FLC, immunofixation, Bence-Jones. C’est une vraie lacune produit, pas une subtilité d’interprétation. L’équipe le voit. Un chantier est en cours.
Ce que Wizey a tout de même livré. Malgré le raté sur le panel d’examens, la sortie n’était pas vide. Elle contenait quelque chose que ChatGPT, non :
Préparez votre consultation : notez quand la faiblesse a commencé, à quelle fréquence et où exactement vous avez mal au dos, et si vous avez eu de la fièvre, des sueurs nocturnes ou une perte de poids involontaire.
— Wizey
Cette liste — fièvre, sueurs nocturnes, perte de poids — c’est le classique dépistage des « symptômes B » pour le lymphome et le myélome. Un patient qui se présente chez l’hématologue avec une note de deux lignes indiquant « trois épisodes de sueurs nocturnes en six mois, environ 3 kg de perte de poids involontaire » fait gagner au clinicien vingt minutes d’interrogatoire et améliore la qualité de la rencontre.
Wizey a également formulé une note métacognitive (« les plages de référence n’étaient pas imprimées sur votre compte rendu — j’ai utilisé des normes reconnues internationalement »), donné une fenêtre d’urgence plus précise (« 1-2 semaines » contre le « dans les semaines à venir » de ChatGPT), et commenté brièvement les traitements en cours.
Conclusion éditoriale. Ce n’est pas une victoire/défaite — ce sont deux modes opératoires différents. ChatGPT s’est comporté comme une checklist de clinicien dans les mains du patient : une liste d’examens à apporter chez le médecin. Wizey s’est comporté comme une préparation à la consultation : symptômes B, formulation plus claire des plaintes, fenêtre d’urgence précise.
Les deux modes sont légitimes. Avoir manqué les examens spécifiques de la MGUS est un point sur lequel nous nous critiquons. Mais si le patient se présente chez un hématologue avec la note de Wizey et que c’est l’hématologue qui prescrit FLC, immunofixation et Bence-Jones (ce qui est son travail), les vingt minutes gagnées sur l’interrogatoire des symptômes B valent beaucoup.
Deux autres cas, le même schéma
Hypothyroïdie infraclinique — femme de cinquante-deux ans
Elle consulte pour fatigue, prise de poids et peau sèche. TSH 6,8 mUI/L (élevée ; normale 0,4-4,0), T4 libre et T3 dans la plage. Cholestérol total 6,8 mmol/L, LDL 4,3. Les deux IA ont correctement atterri sur hypothyroïdie infraclinique plus dyslipidémie. Le diagnostic principal concorde à nouveau.
Elles ont divergé sur une seule phrase. ChatGPT :
Les recommandations actuelles proposent généralement d’initier le traitement si : TSH >6-7, symptômes présents, âge <65. Vous remplissez tous les critères. La lévothyroxine est habituellement prescrite à une faible dose de départ.
— ChatGPT
Superficiellement raisonnable. Sur le fond, c’est une simplification aux conséquences potentiellement nocives. Les recommandations de l’American Thyroid Association et de l’European Thyroid Association pour une TSH dans la plage 4-10 mUI/L disent en réalité l’inverse : la décision est individualisée. Wizey a capté cela :
La décision d’initier le traitement est individualisée : une TSH supérieure à 10 mUI/L justifie généralement le traitement ; une TSH dans la plage 4-10 mUI/L (comme la vôtre) dépend des symptômes, de la présence d’anticorps thyroïdiens, des comorbidités et de la trajectoire dans le temps.
— Wizey
Et il a donné une séquence que ChatGPT a sautée :
Recontrôlez le bilan lipidique au suivi — une fois la fonction thyroïdienne corrigée, le cholestérol se normalise souvent de lui-même.
— Wizey
C’est le détail pivot. Si une femme avec TSH 6,8 et cholestérol 6,8 démarre simultanément lévothyroxine et statine, trois mois plus tard elle peut se retrouver sous une statine dont elle n’a pas besoin : l’hypothyroïdie à elle seule élève le cholestérol. Wizey a ajouté une orientation explicite (endocrinologue), un recontrôle de TSH et T4 libre à 2-3 mois, et une fenêtre d’urgence de « 2-4 semaines ».
Conclusion du cas : les deux ont raison sur le diagnostic. L’un pousse vers le surtraitement et une statine inutile. L’autre construit une séquence.
Le même schéma apparaît dans le cas suivant, sur un autre sujet — et le coût de la simplification s’élève encore.
Périménopause — femme de cinquante ans
Patiente : bouffées de chaleur, sueurs nocturnes, insomnie, baisse de la libido, « brouillard cérébral ». Antécédents familiaux — ostéoporose chez la mère, coronaropathie chez le père. Panel : FSH 42 UI/L, estradiol 45 pmol/L (bas), progestérone 1,2 nmol/L, anti-TPO 68 UI/mL (Hashimoto débutant), vitamine D 22 ng/mL, ferritine 32 μg/L, PTH 68 pg/mL, LDL 3,9 mmol/L. Les deux IA ont atterri sur : transition périménopausique + thyroïdite auto-immune débutante + carence en vitamine D + carence martiale latente + dyslipidémie post-ménopausique.
Elles ont divergé sur le traitement hormonal de la ménopause (THM ; la terminologie plus ancienne est THS, traitement hormonal substitutif ; l’usage actuel privilégie THM). ChatGPT :
Traitement hormonal de la ménopause. Très probablement indiqué. Il réduit les bouffées de chaleur, améliore le sommeil, protège l’os, améliore les lipides. Initié par un gynécologue après évaluation.
— ChatGPT
Wizey a ouvert le même sujet en un cadre de décision :
Compte tenu de votre âge (50 ans), de l’absence de contre-indications et des symptômes marqués — vous êtes dans la « fenêtre d’opportunité » pour initier le THM. Débuter le THM dans les 10 premières années après les dernières règles (vous êtes dans cette fenêtre) est associé au plus grand bénéfice : réduction de 80-90 % des bouffées de chaleur, amélioration du sommeil, de l’humeur, de la libido, protection osseuse et cardiovasculaire, prévention de l’atrophie génito-urinaire.
— Wizey
Ce qui compte, ce n’est pas seulement le chiffre « 80-90 % » — c’est le garde-fou de sécurité que ChatGPT a sauté :
Échographie pelvienne et mammographie — pour mettre à jour votre dépistage (dernière mammographie il y a deux ans, cytologie il y a trois ans). Les contre-indications doivent être écartées avant d’initier le THM.
— Wizey
Dans une grande partie de la culture patiente occidentale, les discussions sur le THM sont soit évitées, soit dominées par des peurs dépassées du cancer du sein héritées de l’ère WHI. Un cadre de décision avec une fenêtre explicite, une taille d’effet quantifiée et le bilan des conditions préalables est rare — particulièrement pour une femme à qui sa gynécologue a dit « c’est l’âge, il faut vivre avec ». Wizey a également ajouté un cadrage émotionnel bref, sans en faire trop :
Vos symptômes ne sont pas « simplement l’âge » ni quelque chose qu’il faut accepter. C’est une situation prise en charge.
— Wizey
Sur les cibles quantitatives, même schéma qu’avec l’homme de 45 ans. ChatGPT : « vitamine D 2000-4000 UI ». Wizey : vitamine D cible 40-60 ng/mL, ferritine 50-100, fer élément 40-80 mg le matin à jeun avec vitamine C, calcium 1200-1500 mg, protéines 1,0-1,2 g/kg de poids corporel. La différence n’est pas la posologie — c’est que la patiente dispose désormais d’une checklist qu’elle peut suivre, pas d’une suggestion générale.
Conclusion du cas : la conversation sur le THM est un champ de mines d’informations dépassées. Un cadre de décision complet ici n’est pas un bonus — c’est le niveau de base du soutien au patient.
Et un cas urgent ?
Sur les quatre cas ambulatoires, le contraste principal portait sur l’orientation, la sécurité et les cibles. Mais il existe une autre dimension qui ne se voit pas dans les scénarios de routine — le triage. Un patient dans un état critique devrait appeler le 15 (SAMU), pas ouvrir une IA. En pratique, il ouvre quand même l’IA. Nous avons passé un cas urgent pour voir comment les deux services gèrent la situation.
Homme de cinquante-deux ans. Sous atorvastatine 40 mg depuis 8 ans pour hypercholestérolémie, plus diabète de type 2 traité par metformine. Plaintes : faiblesse musculaire proximale sévère (il ne peut pas lever les bras, ne peut pas monter les escaliers), douleurs aux épaules et aux hanches, urines foncées depuis cinq jours. Panel : CK 23 171 U/L (normale 30-200 — plus de 115 fois la limite), ASAT 3 851, ALAT 594, myoglobine sérique 3 200, myoglobinurie positive, créatinine 188 μmol/L, DFGe 38 mL/min/1,73 m², potassium 5,3 mmol/L.
Les deux ont vu juste. Diagnostic : rhabdomyolyse induite par statines avec insuffisance rénale aiguë. Étiologie rattachée à l’atorvastatine. Recommandation : hospitaliser. Les deux ont mentionné anti-HMGCR (anticorps anti-HMG-CoA réductase) et anti-SRP — marqueurs de myopathie nécrosante à médiation immunitaire associée aux statines (IMNM).
Au-delà de cela, ils se sont séparés sur trois points.
Triage — la première ligne de la réponse. ChatGPT a organisé sa réponse en 12 blocs : marqueurs, symptômes, causes, traitement. La phrase « rendez-vous immédiatement à l’hôpital » est apparue au neuvième bloc sur douze — après un long mur de texte. Wizey a ouvert le même cas différemment :
Situation critique — hospitalisation immédiate nécessaire. Vos analyses indiquent une atteinte musculaire aiguë sévère (rhabdomyolyse) qui menace la fonction rénale et exige une prise en charge médicale immédiate. Il s’agit d’une urgence médicale.
— Wizey
Et plus loin, dans le bloc d’urgence :
Urgence CRITIQUE — hospitalisation requise dans les heures qui suivent… Si vous ressentez une détérioration brutale (faiblesse intense, rythme cardiaque irrégulier, diminution de la diurèse, confusion) — appelez le 15.
— Wizey
Dans une urgence, la première ligne de la réponse détermine l’issue. Si le patient voit une analyse en 12 blocs avec « rendez-vous immédiatement à l’hôpital » au bloc neuf, il peut perdre 10-15 minutes à lire. L’emplacement du triage, c’est la différence entre « a appelé le 15 » et « a lu jusqu’au bout ».
Raisonnement clinique — le calcul ASAT/ALAT. ASAT 3 851 et ALAT 594 sont faciles à mal interpréter comme une atteinte hépatique sévère : des transaminases qui crèvent le plafond, donc foie. Wizey a fait le calcul explicite :
Rapport ASAT/ALAT = 6,5 (normal autour de 1). Ce degré de prédominance de l’ASAT sur l’ALAT est typique d’une atteinte musculaire, pas d’une atteinte hépatique.
— Wizey
Sans ce calcul, le patient pourrait s’affoler d’une « catastrophe hépatique » — alors que la source des transaminases est ici le muscle. ChatGPT a mentionné le motif en termes généraux, mais n’a pas calculé le rapport.
Répondre au « pourquoi maintenant ? ». Le patient était sous atorvastatine depuis 8 ans. Pourquoi la rhabdomyolyse survient-elle maintenant ?
La rhabdomyolyse peut avoir été déclenchée par : une déshydratation discrète, des interactions médicamenteuses ou une exposition cumulative à la statine sur fond d’aggravation de la fonction rénale (clairance rénale réduite → taux croissants de statine).
— Wizey
ChatGPT a sauté cette question. C’est une question importante — c’est la raison pour laquelle poursuivre la statine après récupération n’est pas une option.
Plan post-hospitalier. Celui de ChatGPT était quasiment inexistant : arrêter la statine, remplissage, surveillance. Celui de Wizey était un plan de sortie complet : hydratation 2-2,5 L/jour, restriction protéique à 0,8-1 g/kg, restriction en potassium, éviter les AINS, CoQ10 100-200 mg/jour, génotypage SLCO1B1, alternatives à la statine (ézétimibe, fibrates, inhibiteurs de PCSK9), surveillance de la fonction rénale et de la CK au minimum tous les 3 mois la première année.
Conclusion du cas. En scénarios de routine, le triage est affaire de tact. En urgence, c’est de la responsabilité clinique. La différence dans la première ligne, dans le calcul du rapport et dans le plan de sortie, c’est la différence entre « information » et « navigation ». Pour que ce soit absolument clair : dans une situation de ce type, le patient doit appeler le 15 — pas ouvrir une IA.
Limites de l’expérience
Nous avions promis une transparence méthodologique. Voici ce qui est fragile dans ce que nous avons fait.
Cinq cas constituent une illustration d’un schéma, pas une statistique. Les conclusions probantes exigent des centaines d’exécutions, idéalement avec des évaluateurs en aveugle et une méthodologie pré-enregistrée. Nous avons vu le même schéma dans chacun des cinq, mais nous reconnaissons que l’échantillon est trop petit. Un lecteur avisé est fondé à dire « montrez-moi 200 cas ». C’est une exigence légitime.
Sur la MGUS, nous avons manqué les examens confirmatoires spécifiques — FLC, immunofixation, Bence-Jones. Ce n’est pas « n’a pas compris le contexte » — c’est une vraie lacune produit. L’équipe le sait, et un chantier sur une meilleure récupération de fragments cliniquement pertinents pour des motifs de panel spécifiques est en cours.
« Lost in the Middle ». Nous nous attendions initialement à ce que, dans le cas de rhabdomyolyse sous statine — un panel de ~70 marqueurs avec l’atorvastatine enfouie au milieu d’une liste de huit médicaments — ChatGPT ne parvienne pas à relier la myopathie à la statine. Cela ne s’est pas produit : le modèle a correctement rattaché l’atorvastatine à la CK élevée. Il est possible que l’effet apparaisse sur des panels plus volumineux (150+ marqueurs), que nous n’avons pas testés. L’hypothèse reste non vérifiée.
Un modèle, une version. Nous avons testé ChatGPT sur GPT-5.4 — un instantané précis dans le temps. Nous n’avons pas testé d’autres LLM publics sur ces cas. Les résultats peuvent différer.
Conflit d’intérêts. Nous sommes l’équipe de Wizey. Pour le limiter : la méthodologie a été figée avant les exécutions (liste de cas, prompt, services), et toutes les sorties sont citées verbatim.
Quand utiliser quel outil
La conclusion n’est pas « utilisez Wizey ». La conclusion, c’est que le choix dépend de la tâche.

ChatGPT est véritablement bon pour :
- Traduire le langage médical en langage courant (« HOMA-IR, ça veut dire quoi au juste ? »)
- Des réponses courtes à une question ciblée (« qu’est-ce que la ferritine ? »)
- Le contexte éducatif sur les maladies, notamment rares
- La formule motivante des « trois choses à faire maintenant » — un premier pas concret
Une IA médicale spécialisée est bonne pour :
- Une lecture structurée d’un panel de laboratoire complet
- L’orientation vers des spécialistes avec des responsabilités spécifiques
- La couche de sécurité — les conditions préalables avant traitement, les signaux d’alerte, les fenêtres d’urgence avec des délais
- Les cibles quantitatives — quel taux atteindre, quelle formulation choisir, quand recontrôler
- La préparation de la consultation — comment formuler les plaintes, quelles questions poser, quoi apporter pour rendre le rendez-vous efficace
Un clinicien réel reste nécessaire. Aucune IA ne peut réaliser l’examen physique, la palpation, ni porter la responsabilité clinique du patient. Un bon clinicien peut encore poser des questions que l’IA n’a pas appris à générer, et voit ce qui ne figure pas sur le compte rendu de laboratoire. Mais arriver préparé — avec une carte de consultations, des plaintes bien formulées et une liste de questions — vaut drastiquement mieux que d’arriver perdu avec une pile de résultats.
La question n’est pas « quelle IA est la plus intelligente ». La question, c’est ce que vous voulez précisément de la technologie : une réponse rapide, ou une analyse structurée de votre situation particulière.
Mini-FAQ
Pourquoi ChatGPT n’a-t-il pas manqué le diagnostic principal dans aucun des cinq cas ? Le diagnostic principal est l’hypothèse la plus probable à partir d’un panel, et sur des schémas cliniques fréquents — syndrome métabolique, hypothyroïdie infraclinique, rhabdomyolyse — les LLM s’en sortent réellement bien. Le problème n’est pas le diagnostic en soi. C’est ce qui vient après : orienter le patient vers le bon spécialiste, les garde-fous de sécurité avant traitement, les niveaux cibles et les intervalles de suivi, les calculs cliniques comme le rapport ASAT/ALAT.
Qu’est-ce qu’une « couche de sécurité » et pourquoi importe-t-elle dans l’interprétation des analyses ? Une couche de sécurité, c’est l’ensemble des conditions préalables et des dépistages à réaliser avant toute initiation de traitement : par exemple, le PSA avant le traitement substitutif par testostérone, ou la mammographie et l’échographie pelvienne avant le traitement hormonal de la ménopause. ChatGPT a systématiquement sauté ces garde-fous, non pas parce qu’il « ne sait pas », mais parce qu’il a été entraîné sur du texte hétérogène d’internet, pas sur des algorithmes cliniques de prise en charge du patient.
Vous n’avez testé que ChatGPT. Et Claude, Gemini ou d’autres modèles ? Uniquement ChatGPT dans cette expérience — GPT-5.4 au niveau Plus. Nous n’avons pas fait passer les mêmes cas dans d’autres LLM. Nous avons publié les panels d’entrée complets et les sorties verbatim, de sorte que quiconque souhaite répéter l’expérience sur d’autres modèles puisse comparer les résultats directement. Nous relaierons votre compte rendu si vous nous l’envoyez.
Cinq cas, c’est peu. Où sont les preuves à grande échelle ? Question légitime. Cinq cas constituent une illustration d’un schéma, pas une statistique. Nous avons vu la même forme dans chacun des cinq, mais nous ne présentons pas cela comme une étude randomisée. Des conclusions probantes exigent des centaines d’exécutions avec évaluateurs en aveugle et une méthodologie pré-enregistrée — c’est la phase suivante sur laquelle l’équipe travaille.
Où sont les données brutes de l’expérience ? Les panels d’entrée complets et les sorties verbatim des deux services sur l’ensemble des cinq cas sont publiés sur une page complémentaire distincte à l’adresse /blog/2026/04/17/wizey-vs-chatgpt-raw-experiment-data/. La méthodologie de reproduction y figure également, si quelqu’un souhaite faire passer les mêmes patients dans d’autres modèles.
En résumé
Le diagnostic correct est la partie facile. Ce qui vient après — la carte des consultations, les garde-fous de sécurité, les niveaux cibles, le pronostic, le triage — c’est là que se joue le vrai travail de soin du patient. C’est la couche où les LLM à usage général s’affaissent systématiquement, et la couche qu’une IA médicale spécialisée est bâtie pour habiter.
Si vous voulez un outil conçu spécifiquement pour ce type d’interprétation de panels multiples de laboratoire, c’est ce que nous construisons chez Wizey. Ce n’est pas un substitut à une consultation clinique — c’est destiné à vous aider à y arriver préparé. Les sorties brutes complètes des deux services sur l’ensemble des cinq cas sont publiées ouvertement, avec la méthodologie de reproduction, au cas où quelqu’un souhaiterait faire passer les mêmes patients dans un autre modèle.


